

写文章的时候,经常需要再往上查找资料,但是有的资料范文是不能复制的,只能自己再一个字一个字的敲,如果文章比较短的话其实也无所谓,但是很多时候是有大量的文献范文不能复制的,还是用手动敲的方法是很耗时耗力的。都什么年代了,从网页上提取个文字还得用手工方法,小编这里就有一个超级简单的方法。
直接网页截图,然后用得力OCR文字识别软件就可以实现了,下面就来看一下,无法复制的网页文字是怎么被复制的。
第一步,先把需要复制的网页文字截图,然后打开得力OCR文字识别软件,然后点击【截图识别】选项。

第二步,点击【添加图片】按钮,把截取的网页图片全部添加进来,然后点击【开始识别】按钮。
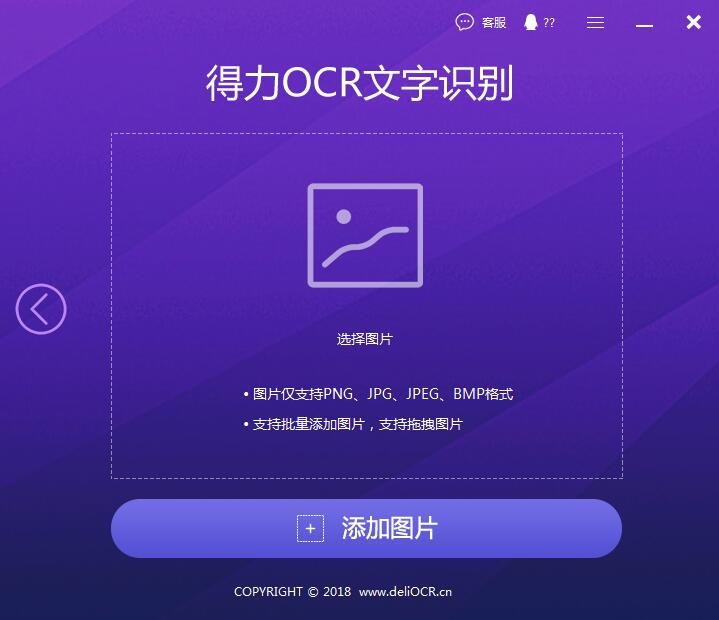
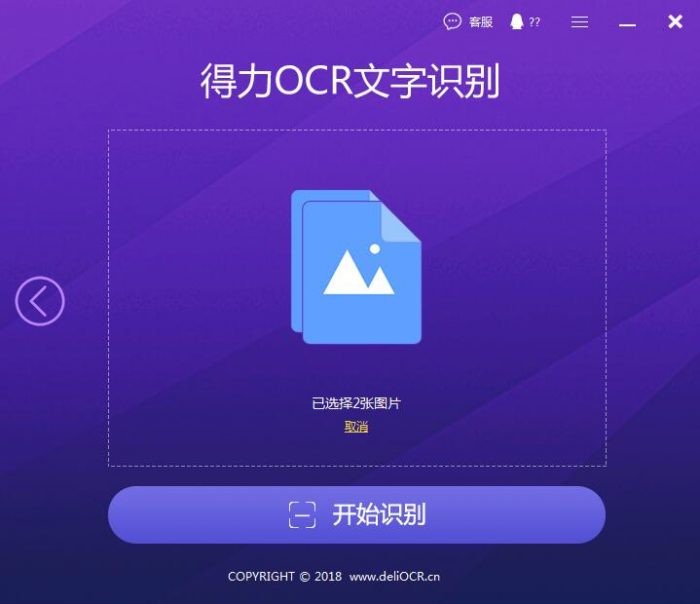
第三步,稍等片刻图片扫描识别完成之后,点击【对比】按钮,一遍确认图片文字识别的准确性。

第四步,确认图片识别的文字无误之后,点击【复制】按钮,然后存成Word文档格式即可。
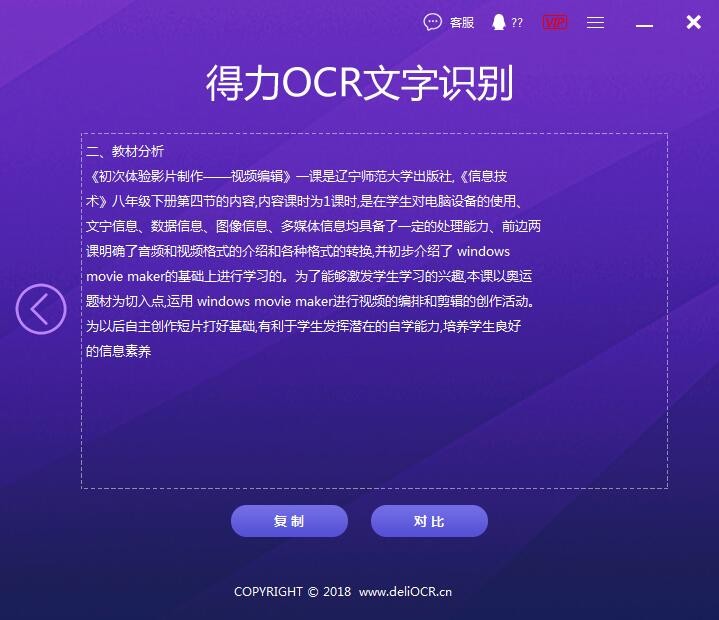
有了得力OCR文字识别软件,不管是什么样的文章都可以被识别为可编辑的文字,不让复制我们就截图呗,反正有得力OCR文字识别软件,分分钟搞定文字复制的问题。好了,今天的内容就分享到这里了,希望对大家有所帮助。








































































 X
X






目前已有0条评论